

سلام به همه بچههای علاقمند به کامپیوتر و برنامهنویسی و هوش مصنوعی. همانطور که میدونین روز به روز دنیای هوش مصنوعی داره وسیعتر میشه و به حوزه مختلف از علوم راه یافته است. ما تصمیم داریم هر هفته با یک مقاله در این حوزه، شمارو با رویداد های دنیای هوش مصنوعی آشنا کنیم و مهمتر اینکه ریاضیات این حوزه رو با ساده سازی به شما دانش آموزان عزیز کانونی توضیح بدیم. در نهایت بتونیم قدم به قدم به کد نویسی در محیط پایتون برای مسئله های جذاب هوش مصنوعی برسیم. پیشنهاد میکنم هر هفته مارو با یک مقاله در این حوزه دنبال کنید.
خب بچه ها، ما در مطالب هفته قبلمون، قانون احتمال شرطی رو بررسی کردیم تا کم کم برسیم به بررسی یک الگوریتم خیلی کاربردی و جذاب به اسم الگوریتم بیز ساده یا Naïve base که همونطور که گفتیم در دنیای Machine learning خیلی کاربردی هست. با فهمیدن این الگوریتم به یک درک کلی از فرایند عملکرد بسیاری از فناوریهای میرسیم. خب پس در ادامه مطلب باهامون همراه باشید تا هر چه بیشتر با این الگوریتم و کاربردهاش آشنا بشیم ! اما برای شروع باید بریم سمت یک تئوری آماری به اسم قانون بیز یا .Bayes theorem
تئوری یا قانون بیز
همونطور که یادتونه، در فرمول احتمال شرطی داشتیم:
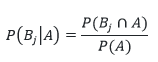
از طرفی، طبق فرمول قانون ضرب احتمال میدونیم که:

با جایگذاری و ادغام این دو تا فرمول میرسیم به فرمول اصلی تئوری بیز که میشه:
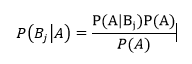
این فرمول رو با جایگذاری رابطه اثبات شده در فرمول محاسبه احتمال بر اساس افراز می تونیم به صورت زیر نیز به دست بیاریم:
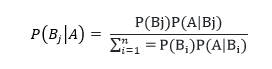
به همین راحتی فرمول اصلی تئوری بیز اثبات میشه. حالا دو تا سوال پیش میاد؛ اولا این فرمول یعنی چی؟ و دوما چه فایدهای در Machine learning داره؟ بزارید جواب سوال اول رو با یک مثال بهتون بگم:
فرض کنید در یک جامعه، احتمال مثبت بودن پاسخ آزمایش کرونا رو پیشامد A و احتمال داشتن کرونا رو پیش آمد B در نظر گرفتیم. بر طبق آمارها، احتمال اینکه در این جامعه یک فرد مبتلا به کرونا باشه 30 درصد هست یعنی P(B)=0.3 . از اونجایی که نتیجه آزمایش کرونا میتونه با کمی خطا همراه باشه، احتمال اینکه نتیجه آزمایش برای یک بیمار کرونایی، مثبت باشه، 80 درصد است؛ یعنی P(A|B)=0.8 و در نهایت، احتمال اینکه آزمایش منفی برای فرد سالم به دست بیاد 70 درصد محاسبه شده است که یعنی P (A'|B') = 0.7. الان می خوایم بدونیم فردی که در این جامعه جواب آزمایشش مثبت شده، چند درصد احتمال داره واقعا مبتلا به کرونا بوده باشه؟ برای حل این مسئله به سمت قانون تئوری بیز میریم که جواب به صورت زیر بدست می آید:
P(B|A) = (0.8*0.3)/ (0.8*0.3) + (1-0.7) *(1-0.3) = 0.24/0.24+0.21=0.53
به این ترتیب ما با استفاده از این تئوری، از طریق احتمال های پیشین که قبلا محاسبه شده است، به احتمال پسین دست پیدا می کنیم که این امر در بسیاری از مواقع بدون استفاده از تئوری بیز بسیار دشوار است. تئوری بیز رو بر اساس احتمالات پیشامدهای پیشین (Prior)، پسین (Posterior)، درست نمایی (Likelihood) و شواهد (Evidence) به صورت زیر نشون میدهیم:
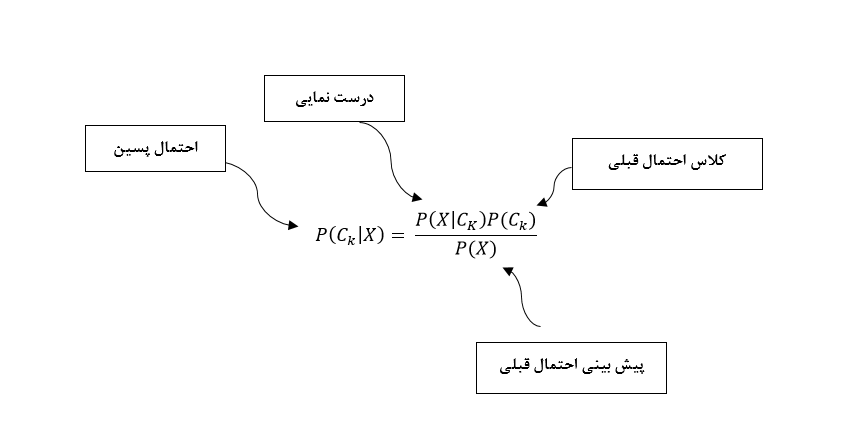
این فرمول ، ما رو به روش های بسیار مهمی تحت عنوان روش های یادگیری بیزی در Machine learning میرسونه که در قسمت بعدی شرح میدیم.
الگوریتم بیز در یادگیری ماشین
همه ما انسان ها در طول روز با پیش آمدهای مختلفی روبرو میشیم که باید با قوه تفکر و بر اساس مشاهدات و تجربیات خودمون تو زندگی، تصمیم هایی رو بر اساس احتمالات بگیریم که به نوعی بهش میگن عدم قطعیت و یا عدم اطمینان . حالا در دنیا هوش مصنوعی هم، یک نرم افزار یا یک ربات برای اینکه بتونه تصمیمات هوشمند بگیره، باید بتونه در کسری از ثانیه بر اساس یک سری احتمالات پیشین، یک پیشامد رو تحلیل کرده و اون رو تشخیص و ارزیابی کنه. برای مثال، امروزه، فناوری هایی وجود داره که می تونه از وضیعت آب و هوا تا چهره یک فرد و اجزای صورت او و همچنین، حالات چهره او، مثل غمگین بودن یا ناراحت بودن رو تشخیص بده. در فناوری های هوشمند، نرم افزار با توجه به داده های پیشینی که بهش داده شده، ویژگی های حالت غمگین یا شاد و غیره براش تعریف شده است .پس با محاسبه احتمال نزدیک بودن حالت عکس فرد به داده های پیشینی که ذخیره داره، از تئوری های احتمالی مانندNaïve bayes یا الگوریتم بیز ساده استفاده می کنه و حالت چهره فرد رو تشخیص میده.

بنابراین الگوریتم بیز ساده، یک روش طبقه بندی بر اساس قضیه بیز با فرض مستقل و جدا بودن پیش بینی کنندهها هست. یعنی به بیان سادهتر، در این الگوریتم فرض میشه که ویژگیها و پیشامدهای بررسی شده ربطی به هم نداشته و کاملا از هم مستقل هستند . برای مثال، هنگام محاسبه احتمال بارش باران در یک سیستم تشخیص آب و هوا، ویژگی هوای ابری با ویژگی سرعت باد بالا مستقل از هم بوده و روابط احتمالی بین پیش آمد ها در نظر گرفته نمیشه. از این رو، ساخت مدلهای دسته بندی براش کار آسون تری هست .به همین دلیل، با وجود سادگی، از بسیاری از الگوریتم های پیچیده کاربرد بیشتری و بهتری در مجموعه های بزرگ داره. از کاربردهای مهم دیگه این الگوریتم میشه به سیتم های تشخیص پزشکی، طبقه بندی اسناد، تحلیل احساسات، طبقه بندی تصویر، دسته بندی اخبار در مرورگرها و اینترنت، تشخیص جملات و دسته بندی در شبکه های مجازی اشاره کرد. در ادامه با یک مثال عملی می خوایم نشون بدیم که نحوه عملکرد این الگوریتم چطوری هست.
دوستان عزیزم؛ برای ارتباط با رتبه برترها صفحه اینستاگرام زیر رو دنبال کنید.

