

سلام به همه بچههای علاقمند به کامپیوتر و برنامهنویسی و هوش مصنوعی. همانطور که میدونین روز به روز دنیای هوش مصنوعی داره وسیعتر میشه و به حوزه مختلف از علوم راه یافته است. ما تصمیم داریم هر هفته با یک مقاله در این حوزه، شمارو با رویداد های دنیای هوش مصنوعی آشنا کنیم و مهمتر اینکه ریاضیات این حوزه رو با ساده سازی به شما دانش آموزان عزیز کانونی توضیح بدیم. در نهایت بتونیم قدم به قدم به کد نویسی در محیط پایتون برای مسئله های جذاب هوش مصنوعی برسیم. پیشنهاد میکنم هر هفته مارو با یک مقاله در این حوزه دنبال کنید.
هفته پیش یه مطلبی براتون نوشتیم در مورد هوش مصنوعی و این هفته رفتیم سراغ یادگیری ماشین و الگوریتمهای موجود در اون. پس اگه مطلب هفته پیش ما رو نخوندید اول برید سراغ اون و بعد مطلب حاضر رو شروع کنید.
اصطلاحات پرتکرار:
قبل از اینکه وارد بحث اصلی بشیم لازمه این اصطلاحات رو یاد بگیریم. پس فقط مفهوم اینارو یاد بگیرید و لازم نیست از همه قسمتاش سردربیارید!
برچسبدار کردنِ اطلاعات(Labeling data): ما انسانها وقتی از دور جسم متحرکی رو میبینیم که دو تا نور ازش خارج شده سریع میگیم که اون باید یه ماشین باشه. این یعنی اینکه اجسام و پدیدهها در ذهن ما برچسبدار شدن و به محض اینکه یه شکل خاصی میبینیم سریع ذهن ما برچسب اون رو (مثلاً ماشین) به یاد میاره. حالا از اونجا که گفتیم هوش مصنوعی نوعی شبیه سازی ماشین با انسانه، برای اینکه ماشین بتونه در فرایند یادگیری، اطلاعات رو درست تشخیص بده دانشمندها از تکنیک برچسبدار کردن اطلاعات (Data labeling) استفاده کردهاند. حالا وقتی ماشین یه حیوانی رو با برچسب گربه میشناسه، در عکسهای جدید توانایی این رو داره که به درستی گربه رو شناسایی کنه و به اشتباه نیفته. تکنیک برچسبدار کردن رو در الگوریتم نظارتشده (Supervised algorithm) استفاده میکنند.
برای اینکه ماشین بتونه اطلاعات جدید و خام رو به کمک اطلاعات برچسبدار شده پیشبینی کنه، از تکنیکهای طبقهبندی و برگشت استفاده میکنه.
طبقهبندی(Classification): هدف از طبقهبندی اطلاعات پیشبینی ارزشهای گسسته(Discrete values) است. ارزش گسسته یعنی اینکه یه چیزی مثلاً یا درسته یا غلط، یا صفره یا یک، یا آشغاله یا آشغال نیست، خلاصه اینکه دوتا ارزش کاملاً متضاد میتونه داشته باشه. شما به وسیله طبقهبندی به ماشین یاد میدید که مثلا اگر فلان محتوا به عنوان ورودی واردِ ماشین بشه باید به عنوان محتوای هرز یا نادرست تشخیص داده بشه. همون کاری که توییتر چند وقت پیش با توییتهایی میکرد که محتوای نادرستی درباره انتخابات آمریکا تولید میکردن. مثلا شما وقتی از ماشین میپرسی که آیا من حقوق بالایی میگیرم یا پایین بر اساس اطلاعات قبلی حقوق شما یا در قسمت بالا میزاره یا پایین.
برگشت(Regression): با این تکنیک ماشین میتونه ارزش واقعی یک ورودی جدید (مثلا یه خونه) رو بر اساس اطلاعات قبلی پیشبینی کنه. مثلاً شما به ماشین یه سری ویژگی در مورد اندازه یه خونه، سال ساختِ اون، چند خوابه بودنِ اون و... قبلاً دادی و ماشین با توجه به این ویژگیها قیمت یه خونه جدید رو براتون پیشبینی میکنه. یا اینکه در مورد مثالی که قبلا درباره حقوق زدیم ماشین با این تکنیک پیشبینی میکنه که کی حقوق شما افزایش پیدا میکنه یا چقدر افزایش پیدا میکنه. خلاصه اینکه برگشت یه چیزی شبیه به همون طبقهبندیه یعنی ماشین سعی داره بر مبنای اطلاعات قبلی ارزش یک چیز رو بسنجه. با این تفاوت که در اینجا سعی داره ارزش واقعی یه چیزی رو تعیین کنه نه اینکه صرفاً اون رو طبقهبندی کنه.
یادگیری ماشین:
قبل از اینکه بریم سراغ انواع الگوریتمهای موجود در یادگیری ماشین اجازه بدید با یه مثال روشن کنیم که یادگیری ماشین چیکار میخواد بکنه. یادگیری ماشین رو برای این تو هوش مصنوعی استفاده میکنن که بتونن تشخیص گفتارِ ماشین رو ارتقاء ببخشن. مثلاً شما از یه اپلیکیشن انتظار دارین که در مورد یه سری چیزا راهنماییتون کنه. ازش میپرسید که نزدیکترین ایستگاه اتوبوس کجاست. به محض اینکه این سوال رو از اپلیکیشن میکنید، این سوال تبدیل به یه سری از کدها میشه. سپس این کدها به وسیله الگوریتمهای موجود پردازش میشن و بعد از این نتیجه متناسب با سوال شما ارائه میشه. این تقریباً تمام کاریه که از یادگیری ماشین انتظار میره. یعنی یه کاری بکنی که ماشین منظور تو رو بفهمه و بدون دخالت مستقیم انسان بهت جواب بده.
برای اینکه بتونیم بهتر الگوریتمهای موجود تو یادگیری ماشین رو بفهمیم، اونا رو تحت سه عنوان کلی طبقهبندی میکنیم:
- یادگیری نظارتشده
- یادگیری نظارتنشده
- یادگیری تقویتی
1- یادگیری نظارتشده(Supervised learning):
تو این نوع یادگیری ما یه سری داده برچسبدار شده رو در اختیار ماشین قرار میدیم و ماشین به کمک این دادهها یه سری چیزارو پیشبینی میکنه. این نوع از یادگیری یه جور تخمینِ کارکرده. یعنی اینکه ما یه الگوریتمی میسازیم که به بهترین وجه داده ورودی رو توصیف میکنه و یه جورایی ارزشش رو تخمین میزنه یا اینکه طبقهبندیش میکنه. مثلاً شما در مورد یه کاری از اپلیکیشن سوال میکنید و اپلیکیشن پیشبینی میکنه که شما تو اون کار موفق خواهید شد یا نه. یا اینکه اینستاگرام عکس دوست شما رو برچسبدار میکنه و اگه دوستتون عکس جدیدی از خودش گذاشت سریع شناساییش میکنه و به شما خبر میده. در آخر این رو اضافه کنم که از این جهت به این یادگیری میگن نظارت شده که آدما دادههای برچسبدار شده رو به ماشین میدن تا به کمک اونا بهتر بتونه کار کنه. یعنی عملاً آدما رو ماشین نظارت دارند.
اینا چند نمونه از الگوریتمهایی هستند که تو یادگیری نظارتشده استفاده میشن:
- نزدیکترین همسایه(Nearest neighbor)
- بیزِ ساده(Naive Bayes)
- شبکههای عصبی(Neural networks)
2- یادگیری نظارت نشده(Unsupervised learning):
اینجا ماشین به وسیله دادههای بدون برچسب آموزش داده میشه. در یادگیری نظارت نشده انسان دیگه دخالتی نداره و ماشین باید خودش یه سری الگوها از دادهها به دست بیاره و شمارو راهنمایی بکنه. تو این نوع یادگیری انسان نمیدونه دقیقاً تو دادهها باید دنبال چه چیزی باشه و ماشین ارتباط دادهها رو بهش میگه. اینجا دیگه هیچ داده برچسبدار در دسترس ماشین نیست و ماشین فقط میتونه یه سری قواعد از دادههای ورودی استخراج بکنه، دنبال الگوها باشه، دادهها رو خلاصه بکنه و اونارو دسته بندی کنه.
با چندتا مثال ساده شیوۀ کار یادگیری نظارت نشده رو بهتر یاد میگیرم. فرض کنید یک شرکت ارتباطات میخواد نرخ ریزش مشتری رو کاهش بده. این شرکت شروع میکنه مدت مکالمه و میزان مصرف اینترنت مشتریهاش رو مطالعه بکنه و متوجه میشه در حالی که مدت مکالمهی عدهای از مشتریها بالاست، بقیه مشتریها مصرف اینترنت بالایی دارند. سپس ماشین مشتریها رو بر اساس میزان مصرف اینترنت و مدت مکالمه دستهبندی میکنه. سپس شرکت براساس این دستهبندی یا خوشهبندی به گروههایی که مصرفِ بیشتر اینترنت دارند کاهش نرخ اینترنت و به دستهای که مدت مکالمهشون بالاست کاهش نرخ مکالمه اعطا میکنه.
الگوریتمهای معروف تو این نوع یادگیری عبارتند از:
- الگوریتمهای خوشهکننده(Clustering algorithm)
- الگوریتمهای قاعده وحدتبخشی(Association rule algorithm)
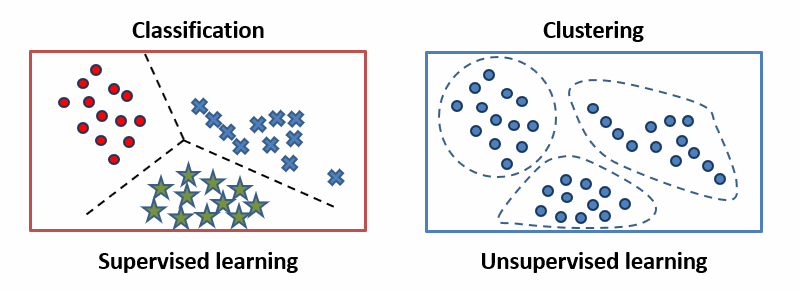
شکل زیر تفاوتی از یادگیری بانظارت و بدون نظارت را نشان میدهد، همانطور که میبینید در یادگیری بدون نظارت الگوریتم داده ها را در خوشه هایی جدا میکند و هیچ برچسبی بر آنها در نظر گرفته نمی شود (همه داده ها یک رنگ دارند) اما درالگوریتم بانظارت داده ها از قبل دارای برچسب بودند و الگوریتم با روش نظارت شده مسئله را حل کرده است و درنهاست در این مثال سه رنگ متفاوت را از هم جدا کرده است.
3- یادگیری تقویتی(Reinforcement learning):
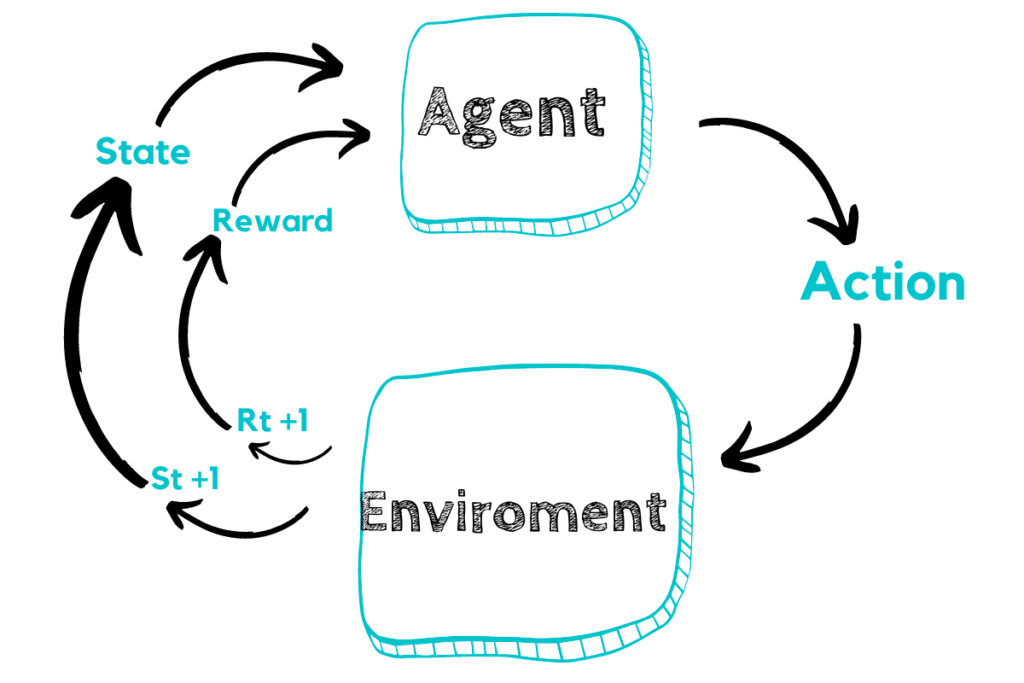
در این یادگیری به ماشین یاد میدن که چطور مسائل رو بر اساس آزمون و خطا حل بکنه. قضیه اینجوری شروع میشه که یک عامل با محیط اطرافش ارتباط برقرار میکنه. این عامل میخواد به یک هدف در چند مرحله دست پیدا کنه. اجازه بدید با یه مثال پیش بریم. یک اتوموبیلِ تمام خودکار میخواد تو جهان واقعی رانندگی کنه و هدفشم اینه که شما رو از خونهتون به محل کارتون برسونه، یه جوری که به مانعهایی که سر راهش است برخورد نکنه. محیط اطراف یه موقعیتی داره. این موقعیت شامل محل قرارگیری اتوموبیل، وضعیت جاده، و محل قرارگیری خودروهای دیگه میشه. اتوموبیل این موقعیت رو از طرق حواسی مثل دیدن یا شنیدن و... درک میکنه. بعلاوه اتوموبیل میتونه یه سری کارا بکنه مثلاً جلو بره، عقب بره و به چپ یا راست بره. همه این کارا نه تنها وضعیت این اتوموبیل رو بلکه وضعیت بقیه خودروها و موانع رو نیز تو جاده تغییر میده. و بالاخره اتوموبیل وقتی به هدفش نزدیک میشه یه سری سیگنالهای مژدهدهنده دریافت میکنه. عاملِ ما که این اتوموبیل باشه از طریق این سیگنالها متوجه میشه که کدوم یک از کاراش موفقیتآمیز بوده کدوم نه. به عبارت دیگه ما میتونیم برای هر حرکت درست یا غلط اتوموبیل یه امتیاز مثبت یا منفی بدیم. و انقد از این امتیازها بهش میدیم که بالاخره اتوموبیل از طریق آزمون و خطا متوجه میشه چطوری در اون محیط به نحو احسن رفتار کنه.
الگوریتمهای رایج در این نوع از یادگیری عبارتند از:
- یادگیری کیو(Q-Learning)
- تفاوت موقتی(Temporal difference)
- شبکههای متعارض عمیق(Deep adversarial networks)
واژگان تخصصی:
عامل = Agent
الگوریتم قاعده وحدتبخشی = Association rule algorithm
طبقهبندی = Classification
الگوریتم خوشهکننده = Clustering algorithm
داده برچسبدار = Labeling data
یادگیری ماشین = Machine learning
بیزِ ساده = Naive bayes
نزدیکترین همسایه = Nearest neighbor
شبکههای عصبی = Neural networks
برگشت = Regression
یادگیری تقویتی = Reinforcement learning
یادگیری نظارتشده = Supervised learning
یادگیری نظارتنشده = Unsupervised learning
یادگیری کیو = Q-Learning
تفاوت موقتی = Temporal difference
شبکههای متعارض عمیق = Deep adversarial networks
منابع:
- Supervised and Unsupervised Learning In Machine Learning | Machine Learning Tutorial | Simplilearn - YouTube
- Types of Machine Learning Algorithms You Should Know | by David Fumo | Towards Data Science
- What is Reinforcement Learning? - YouTube
